
가장 많이 본 뉴스
2025.12.08 (월)

언론단체, 네이버 AI 뉴스 학습에 저작권 침해 소송
- 가

피해액 수백억 원 배상 청구 전망
최수진 “저작권 가이드라인 필요”
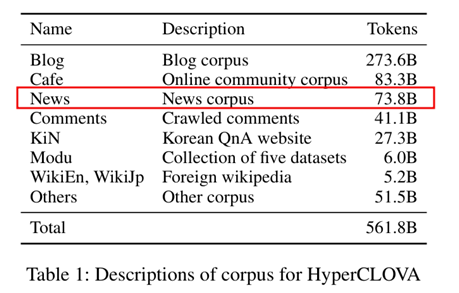 한국방송협회, 하이퍼클로바 핵심 연구 논문 중 학습데이터 부분. 최수진 의원실 제공.
한국방송협회, 하이퍼클로바 핵심 연구 논문 중 학습데이터 부분. 최수진 의원실 제공.
 한국방송협회, AI 뉴스콘텐츠 학습 인정 답변 내용. 최수진 의원실 제공.
한국방송협회, AI 뉴스콘텐츠 학습 인정 답변 내용. 최수진 의원실 제공.
한국신문협회 등 언론 단체가 네이버의 생성형 AI 모델인 하이퍼클로바(HyperCLOVA)에 대해 수백억 원에 달하는 저작권 피해 배상 소송을 벌이고 있지만, 주무 부처인 과학기술정보통신기부가 관련 제도개선에 미온적이라는 지적이 나왔다.
국회 과학기술정보방송통신위원회 소속 국민의힘 최수진 의원은 13일 “전세계적으로 AI 산업발전을 위해 정부가 주도적으로 저작권 관련 규제와 가이드라인 마련에 앞장서고 있다”면서 “국가 AI 경쟁력 확보를 위해서는 저작물 데이터 활용과 관련하여 정부가 앞장서 제도개선책을 마련해야 한다”고 지적했다.
최 의원에 따르면 한국방송협회는 네이버와 네이버클라우드 주식회사를 상대로 지난 1월 AI 저작권침해에 대해 총 6억 원을 배상하도록 하는 손해배상소송을 제기했다. 최 의원은 부분 피해액이 5억 원을 넘길 경우 배상액 조정과정을 거치는 점을 감안해 볼 때 향후 한국방송협회가 수백억 원에 달하는 피해보상액을 청구할 것으로 예상했다. 한국신문협회도 네이버가 신문 기사 콘텐츠를 AI 학습에 무단 사용했다며 지난 4월 공정위에 신고했고 공정위 판단을 토대로 개별 언론사들의 손해 배상 청구가 잇따를 것으로 예상됐다.
한국방송협회는 소장에서 “네이버가 대규모 언어 모델(LLM) 하이퍼클로바 등을 개발하는 과정에서 학습에 쓴 블로그, 카페, 뉴스, 댓글, 지식인, 국립국어원의 모두 말뭉치, 위키피디아 등 데이터 가운데 뉴스는 13.1%로 상당한 비중을 차지하고 있다”고 주장했다. 또, 네이버의 AI 서비스 자체도 ‘뉴스를 학습했느냐’는 질문에 인정하는 답변을 내놓고 있지만, 네이버는 뉴스 콘텐츠 이용에 대한 어떤 허락도 받은 적이 없다고 비판했다.
한국신문협회도 지난 4월 공정위에 네이버가 시장 지배적 지위와 거래상의 우월적 지위를 이용해 뉴스 데이터를 일방적으로 LLM 개발과 운영에 사용했다고 신고했고 조사가 진행 중이다. 신문협회는 “네이버의 행태는 저작권 침해 행위일 뿐 아니라 언론사의 뉴스 콘텐츠 기반 사업 활동을 심각하게 침해한다”며 시장지배적 지위를 남용한 사업 활동 방해라고 지목했다. 신문협회는 하이퍼클로바뿐만 아니라 네이버의 ‘큐:’, ‘AI 브리핑’ 등 생성형 AI 기반 검색 서비스 역시 뉴스 기사의 주요 내용을 무단 복제·요약·재구성해 답변 형태로 제공한다고 저작권 침해라고 보고 있다. 그러면서 “AI 요약 등 과정에서 원문을 왜곡하거나 중요 정보를 누락하는 등의 부작용도 발생하고 있다”고 지적했다.
AI 학습에 뉴스 사용을 둘러싸고 언론 단체들과 네이버의 갈등이 타협점을 찾지 못하고 있는 가운데 AI 정책 주무 부처인 과기정통부가 AI 연구와 산업 발전의 필수기반인 저작권 문제와 분쟁 해결에 손을 놓고 있다는 비판도 제기된다. AI 학습에 뉴스 무단 사용에 대한 질의에 과기정통부는 “저작권자의 권리 보호와 AI 산업 혁신을 위한 활용 간에 균형감 있는 검토가 필요한 사안으로 관계부처와 긴밀히 협력해 대안을 마련하겠다”는 원론적인 입장만 내놨다.
최수진 의원은 “AI 산업을 둘러싼 저작권 문제가 산업간 법적 분쟁이 되고 있는데 주무 부처가 제도 개선과 가이드라인 마련에 수수방관하고 있다”며 “AI 학습 관련 저작권 면책 요건과 저작권자에 적절한 보상 체계를 마련하는 등 국회와 정부가 적극 제도에 하루빨리 나서야 한다”고 촉구했다.
김종우 기자 kjongwoo@busan.com
당신을 위한 AI 추천 기사
실시간 핫뉴스








[48789] 부산시 동구 중앙대로 365 (수정동) | 전화번호 : 051)461-4114 | 이메일 : webmaster@busan.com
등록번호 : 부산아00091 | 등록일자 : 2011년 5월24일 | 발행·편집 겸 인쇄인 : 손영신 | 청소년보호책임자 : 이재희
모든 콘텐츠를 커뮤니티, 카페, 블로그 등에서 무단 사용하는것은 저작권법에 저촉되며, 법적 제재를 받을 수 있습니다.
COPYRIGHT (C) 2016 부산일보사 ALL RIGHTS RESERVED.